
We beginnen ons verhaal bij de bescheiden monnik Gregor Mendel, die leefde van 1822 tot 1884. Door erwtenplanten te kruisen in de tuin van het klooster in Brno, ontdekte hij hoe erfelijke eigenschappen worden doorgegeven. We spreken daarom nog altijd van de wetten van Mendel. Opmerkelijk is dat zijn ontdekking lange tijd nauwelijks aandacht kreeg. Toch vormt zijn werk het begin van een zoektocht die tot op vandaag doorgaat: hoe werkt erfelijkheid precies, en wat kan de cel ons daarover vertellen?
Al snel werd duidelijk dat dit onderzoek niet alleen belangrijk is om erfelijkheid te begrijpen. Het helpt ons ook om ziekten beter te verklaren en nieuwe mogelijkheden te zien om langer gezond te blijven leven.
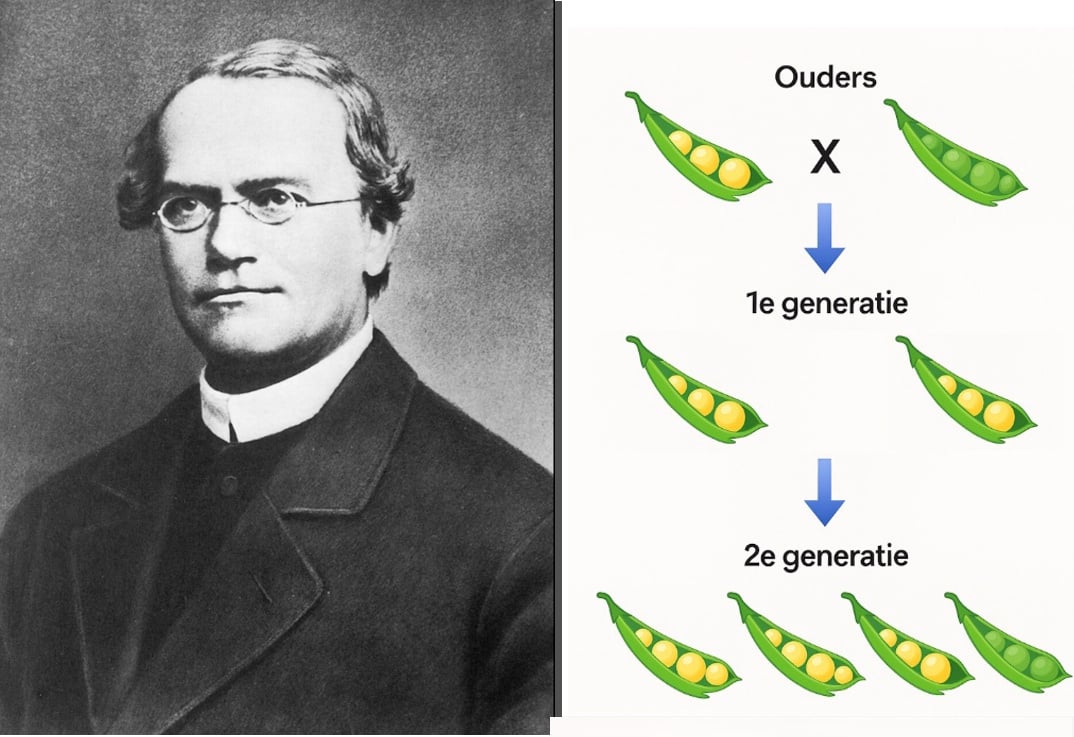
Hier zie je het klassieke voorbeeld waarmee de inzichten van Mendel vaak worden uitgelegd.
Stel dat we twee erwtenplanten kruisen. De eigenschap geel blijkt dominant te zijn. Dat zie je terug in de eerste generatie: de erwten zijn dan geel. In de tweede generatie verschijnt ook de niet-dominante variant groen.
Uit de studies van Mendel blijkt dat erfelijke eigenschappen niet verdwijnen, maar verborgen aanwezig kunnen blijven. Mendel ontdekte zo vaste patronen in de manier waarop eigenschappen worden doorgegeven.
De volgende video laat dit zien in een heldere animatie.
Je kunt ondertiteling aanzetten aan de hand van het tandwieltje rechtsonder.
1. De ontdekking van de “onzichtbare pakketjes”
Toen de monnik Gregor Mendel rond 1860 tienduizenden erwtenplanten met elkaar kruiste, ontdekte hij de basisregels van de erfelijkheid. Voor die tijd dachten mensen dat eigenschappen van ouders als een soort verf door elkaar werden gemengd. Mendel liet zien dat eigenschappen (zoals de kleur van de erwt of de vorm van de plant) in vaste, onzichtbare “pakketjes” werden doorgegeven. Hij noemde deze pakketjes toen factoren.
2. Het grote gat in de tijd
Het zou nog heel lang duren voordat we de biologie erachter begrepen. Toen Mendel zijn onderzoek in 1866 publiceerde, begreep bijna niemand hoe belangrijk het was. Zijn werk lag tientallen jaren te verstoffen.
Pas rond 1900 werd zijn werk herontdekt en kregen zijn “factoren” later de naam genen. Nog later ontdekten wetenschappers dat deze genen opgeslagen liggen in het DNA. In 1953 werd duidelijk hoe de structuur van DNA eruitziet: als een dubbele helix.
Kortom: Mendel ontdekte eigenlijk dat er een genetisch kookboek bestond en hoe dat boek van generatie op generatie werd doorgegeven. Maar pas honderd jaar later ontdekten we dat de teksten in dit boek geschreven waren met de DNA-letters A, C, G en T!

De Amerikaanse bioloog Thomas Hunt Morgan zou 22 boeken en 370 artikelen schrijven.
Maar zijn allergrootste meesterzet was de casting van zijn kleine hoofdrolspeler. Morgan bombardeerde het doodgewone fruitvliegje (Drosophila melanogaster) tot de absolute superster van zijn lab. Dankzij zijn baanbrekende experimenten met deze fruitvliegjes werd dit vliegje het allerbelangrijkste proefdier in de moderne genetica.
Hij was tevens de oprichter van de prestigieuze biologie-afdeling van het California Institute of Technology (Caltech) die in de jaren erna maar liefst zeven Nobelprijswinnaars zou afleveren.
Na de herontdekking van de wetten van Mendel rond 1900 ging Morgan mutaties (kleine veranderingen in het erfelijk materiaal) onderzoeken bij de fruitvlieg Drosophila melanogaster.
Met zijn experimenten maakte hij duidelijk dat genen op chromosomen liggen. Dat inzicht werd een van de fundamenten van de moderne genetica.
Toen hij in 1933 de Nobelprijs kreeg, was dit de eerste keer dat de prijs werd uitgereikt voor genetica…
Je kunt de ondertiteling inschakelen via het tandwieltje rechtsonder.

Antwoord: Mensen dachten dat eigenschappen van ouders simpelweg als een soort verf door elkaar werden gemengd. Mendel bewees echter dat eigenschappen worden doorgegeven in vaste “pakketjes” (factoren).
Antwoord: Bijna 35 jaar. Hij publiceerde zijn werk in 1866, maar pas rond 1900 werd het herontdekt door andere wetenschappers.
Antwoord: De afdeling leverde in de jaren na de oprichting maar liefst zeven Nobelprijswinnaars af.
Antwoord: De code bestaat uit een extreem lange streng van vier verschillende ‘letters’ (C, G, T en A). In totaal bevat het menselijk DNA wel drie miljard van deze letters.
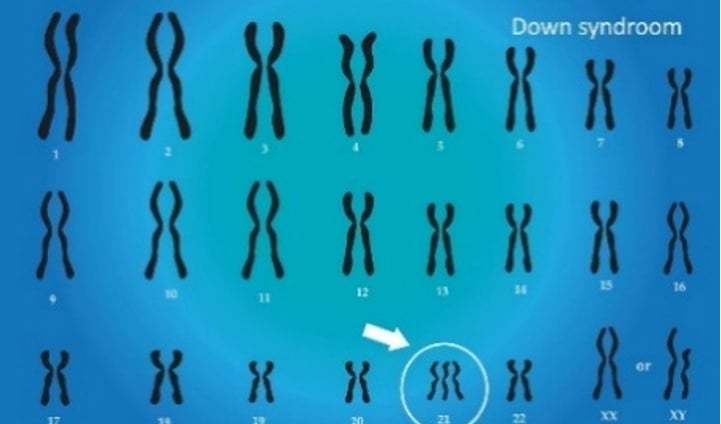
Iedereen kent wel het syndroom van Down. De figuur toont de chromosomen van iemand met dit syndroom: je ziet bij positie 21 geen standaard paar, maar een compleet derde chromosoom. Deze afwijking werd in 1959 ontdekt door een Franse onderzoeksgroep. Met hun microscopen konden zij de chromosomen – de fysieke ‘boeken’ van onze erfelijkheid – destijds letterlijk zien en tellen. Hoewel de structuur van het DNA-molecuul met zijn vier letters (A, C, G en T) enkele jaren eerder was ontdekt, wisten wetenschappers nog nauwelijks hoe die informatie moest worden gelezen.
Hoe die miljarden letters precies de code van het leven vormden, was het volgende grote raadsel dat de wetenschap moest zien te kraken.
Schilderij gemaakt naar de foto van Barrington Brown
De ontdekking van de dubbele helixstructuur van DNA in 1953 kwam op naam van de onderzoekers James Watson (op de afbeelding links) en Francis Crick.
De ontdekking van het DNA is een geweldige mijlpaal in de geschiedenis van de moleculaire biologie.
Het is bekend dat Watson en Crick voor hun ontdekking gebruikmaakten van cruciale gegevens van Rosalind Franklin — laten we zeggen: geleend zonder haar toestemming. Maar ja, Rosalind was een vrouw, en in die tijd werd de positie van vrouwen in de wetenschap nog sterk als ondergeschikt ervaren. Uiteindelijk gingen Watson en Crick met de eer strijken, terwijl de bijdrage van Franklin cruciaal was.
Tot op de dag van vandaag blijft dat een smet op die ontdekking. Ook de wetenschap kent haar schaduwkanten als het gaat om eer en erkenning.

logo Human Genome Project
Na de ontdekking van de dubbele helix in 1953 wisten wetenschappers inderdaad wélk alfabet werd gebruikt om genetische codes te beschrijven (dus de bindingen die worden aangeduid met de letters A, C, G en T) en hoe DNA verder in elkaar zat. Maar ze hadden de technologie nog lang niet om de volgorde van die letters (de daadwerkelijke code) uit te lezen.
Om een vergelijking met boeken te maken: ze wisten nu hoe de bladzijden in elkaar zaten en dat de tekst met slechts vier letters was geschreven, maar ze hadden de ‘leesbril’ nog niet uitgevonden. Het boek lag voor hen op tafel, maar ze konden de zinnen erin nog niet lezen.
Het zou nog tientallen jaren duren voordat we dat echt konden:
Eind jaren ’70: Pas in 1977 bedacht de Britse wetenschapper Frederick Sanger een slimme chemische truc (Sanger-sequencing) waarmee het voor het eerst lukte om de exacte lettervolgorde van relatief korte stukjes DNA af te lezen.
Jaren ’90 tot 2003: Het daadwerkelijk uitlezen van héle lange, complete strings – zoals al het DNA van een mens (alle 3 miljard letters) – was zo’n gigantische en complexe klus dat het pas in 2003 werd afgerond met het beroemde Human Genome Project. Tussen de ontdekking van de structuur en het volledig kunnen lezen van een menselijk genoom zat dus maar liefst 50 jaar.
Overigens werd wel aangekondigd dat het hele genoom in kaart is gebracht, maar in feite ontbrak nog een heel klein stukje.
De échte 100% kwam pas in 2022
Pas heel recent, in maart 2022, is het een nieuwe internationale groep wetenschappers (het Telomere-to-Telomere of T2T-consortium) gelukt om met gloednieuwe, veel geavanceerdere scantechnieken ook die allerlaatste, ingewikkelde 8% uit te lezen. Pas vanaf dat moment is het menselijk genoom (alle ruim 3 miljard letters verdeeld over de chromosomen) écht voor de volle 100% naadloos uitgelezen en bepaald.
Telomeer
Een telomeer is letterlijk het uiteinde van een chromosoom. De beste manier om je een telomeer voor te stellen, is door te denken aan een schoenveter. Aan het uiteinde van een veter zit zo’n handig plastic buisje (een nestel) dat ervoor zorgt dat de veter niet gaat rafelen. Een telomeer doet precies hetzelfde, maar dan voor jouw kwetsbare DNA!
Hoe zit het dan met variaties tussen personen onderling?
Het referentiegenoom uit het Human Genome Project was geen volledige kopie van één persoon, maar een samengestelde standaard op basis van DNA-materiaal dat voor onderzoek beschikbaar was. Je kunt het zien als een soort standaardkaart van het menselijk genoom.
Waarom is deze standaard blauwdruk zo belangrijk?
Dankzij zo’n referentie kunnen artsen en onderzoekers het DNA van een patiënt vergelijken met een standaard. Daardoor wordt het veel makkelijker om te zien waar verschillen zitten die met een ziekte te maken kunnen hebben. Zonder zo’n standaardkaart zou zoeken in meer dan 3 miljard DNA-letters bijna onbegonnen werk zijn.
De sprong van “we hebben de data” naar “we begrijpen wat het betekent” wordt nu voor een gigantisch deel gedreven door Artificial Intelligence (AI) en Machine Learning. Vroeger was het vergelijken van DNA vooral een soort domme, digitale zoek-en-vind-opdracht. Tegenwoordig doet AI veel meer dan dat.
Hier is waarom AI tegenwoordig onmisbaar is in dit proces:
1. Omgaan met extreme hoeveelheden data (en ruis)
Het uitlezen van DNA levert gigantische, rommelige bestanden op. De scanapparaten maken soms zelf leesfouten. AI-systemen (zoals DeepVariant, ontwikkeld door Google) zijn getraind om de ruwe data razendsnel te analyseren en de fouten van het apparaat te onderscheiden van de échte biologische spelfouten in het DNA van de patiënt. Dit gaat veel sneller en nauwkeuriger dan eerdere software.
2. Bepalen of een spelfout onschuldig of gevaarlijk is
Dit is misschien wel de allergrootste doorbraak. Elk mens heeft miljoenen kleine afwijkingen ten opzichte van het referentiegenoom. Veruit de meeste daarvan zijn volkomen onschuldig (het is bijvoorbeeld gewoon de reden dat jij bruine ogen hebt en iemand anders blauwe). Als een simpele computer alleen zegt: “Hier staat een T in plaats van een C”, weet een arts nog niks.
AI-modellen (zoals AlphaMissense) kunnen tegenwoordig voorspellen wat die spelfout daadwerkelijk doet. De AI leert hoe een gezond eiwit gebouwd hoort te worden en voorspelt of dat ene verkeerde lettertje de boel zal laten instorten (wat leidt tot een erfelijke ziekte) of dat het geen kwaad kan.

AI vergt enorme computercapaciteit
3. Complexe patronen ontdekken
Sommige ziektes worden veroorzaakt door één simpele tikfout in één gen. Maar aandoeningen zoals diabetes, schizofrenie of bepaalde soorten kanker ontstaan door een uiterst complexe combinatie van honderden piepkleine, subtiele variaties verspreid over ál je chromosomen. Voor een mens (of standaard software) is dat niet te overzien, maar AI is een ster in het vinden van verborgen patronen in de data van miljoenen patiënten.
Antwoord: Watson en Crick gebruikten cruciale gegevens van onderzoekster Rosalind Franklin zonder haar toestemming of medeweten. Terwijl zij met de eer streken, werd haar onmisbare bijdrage destijds genegeerd.
Antwoord: Men kende wel het alfabet (A, C, G en T), maar de technologie om de miljarden letters in de juiste volgorde uit te lezen (de ‘leesbril’) ontbrak nog. Het Human Genome Project werd pas in 2003 afgerond.
Antwoord: Het Telomere-to-Telomere (T2T) consortium. Zij wisten de laatste 8% uit te lezen, waaronder de telomeren (de uiteinden van chromosomen), die essentieel zijn voor het begrijpen van veroudering.
Antwoord: De AI voorspelt of een veranderde letter de structuur van een eiwit laat “instorten” (schadelijk) of dat de verandering onschuldig is. Zonder AI is het voor mensen bijna onmogelijk om de betekenis van miljoenen kleine variaties te overzien.
Antwoord: Bij complexe ziektes is er niet één duidelijke spelfout, maar gaat het om een combinatie van honderden subtiele variaties verspreid over het hele DNA. AI is extreem goed in het herkennen van die verborgen patronen in enorme hoeveelheden data.
Om dit te bekijken heb je een actief lidmaatschap nodig.
Ik wil meer weten Sluiten